|
I've been working on getting the report up and running using Metasys data instead of the data logged by my own systems. This involves converting the format of the Metasys data into the format accepted by the permanent database `TempAndCO2Log`. This process was lengthier than I anticipated it would be, but once I had figured it out I still had some obstacles remaining.
First, the system was having trouble indexing although the indices of the data table within the database and the indices of the table I wanted to add in looked identical. I was able to debug this successfully when I realized that I had to set the index of the new table to the room number because the database had the room number as the index (it just didn't look like it when it was printed). Next, I got some ValueErrors like this one: ValueError: could not convert string to float: '2020 Sept - AHS ZN-T OA-T & CO2.csv' I was confused as to why I had any kind of data point with a .csv at the end of it, let alone something the program was trying to read as a float! Finally, I figured out that there was some descriptive information at the bottom of the original spreadsheet, that had somehow filtered its way into the data. In fact, the string above had been mistakenly read as a CO2 value! After adding lines to delete the bottom couple of rows from the original file, I ran into another issue with the permanent database -- now that the faulty rows were in the database, it was still throwing errors! I tried running some SQL commands like this one: `DELETE FROM TempAndCO2Log WHERE Timestamp='Metasys File'` However, these commands didn't actually delete anything from the database -- I'm not quite sure why and will try to figure it out in the future. On the other hand, I was able to go into the database using the database browser we had and get rid of all the rows where the timestamp was set to 'Metasys File.' This fixed the problem in the short-term, but for the future, I still want to figure out why the SQL didn't work. After that, I finally was able to get to the point where I was running generate_historical_report on the Metasys data! However, this is not a process free from errors. As the standard story goes, the little elves descended on my code at some point since July -- generate_historical_report seems to be having some data type/rounding issues, not only with the Metasys data, but with the old data that my systems had logged before (and from which I have successfully generated reports). I'm going to continue looking into this issue in the next few days and hopefully figure out what went wrong. For more documentation on all of this, see the issue history on the GitHub repository. A few weeks ago, I made a breakthrough! I was able to successfully use the .melt() and .pivot_tables() functions to effectively do a total rearranging of the data. I now have a rough version of the program that converts the data from the Metasys format into the format accepted by my systems. I'm currently working on testing a full report directly from the Metasys data -- more updates to come!
Also, I met with the recruits one or two times since the last time I've updated this blog -- they are now beginning the same Coursera courses that I completed during my independent study! :) Over the past month or so, a lot of exciting things have happened!
First, I've continued meeting with the group of new recruits. We've mainly been working on figuring out the logistics of starting Energize projects while adjusting to a new hybrid school schedule. They've spent some time exploring the data in their chosen areas of expertise as well. In the next couple of weeks, they will officially start their projects. For me personally, I've been working on a new version of the reporting software that pulls data directly from Metasys instead of relying on 15-minute logs I create myself. This is really important because it means the scope of data that my software can produce reports about is much wider, and because Metasys is a widely used system, which means that I can adapt the software to produce reports about almost any school or building. However, I've also been busy with the new hybrid schedule, and converting the data from Metasys into the format accepted by my software has proven a bit of a challenge so far -- I'll put more updates on that here the next time I continue to work on it. Finally, I presented a status update on this work to the Andover Green Advisory Board at their Wednesday meeting. I'm really grateful to them for giving me the awesome opportunity to present!! I just realized - I never updated this blog after I was featured on CNBC as a HomeGROWN Hero for my teaching initiatives!
Here's the full article: https://grow.acorns.com/teenager-teaches-kids-to-code-in-quarantine/ I was also featured on the CNBC television special that aired in July. This was a really awesome and exciting experience for me! NEWS: The Eagle-Tribune and Andover Townsman wrote an article about my teaching initiatives! Link:
https://www.eagletribune.com/news/merrimack_valley/hometown-hero-ahs-student-15-teaches-coding-during-covid-19/article_b16f13d8-ba4b-519b-a4d6-2108aaa5d5d4.html Over the last couple of weeks, I've also continued working on the visualization component of the reporting engine: I've focused on refining the look of the visualizations and adding a table of rooms with likely sensor issues to the end of the report. I still need to fix formatting & spacing issues with this sensor table, which will conclude the first stage of the development process. Working with matplotlib has been really fun! :) Over the last couple of weeks, a few really exciting things happened: 1. I was named Andover Youth Services' Youth of the Week because of the virtual teaching initiatives I started there! I really appreciate that Energize Andover gave me the freedom to start running a virtual Python class with a group of 5 girls, an experience I eventually used to start virtual technology classes through the Youth Services. 2. While I recently began a summer internship, I have still been working on my Energize projects in my free time. Kate, the PhD student working with Energize through the BU URBAN program, helped me figure out the best way to visually represent the data using matplotlib. I have written a script that generates a PDF of the following visualizations:
I have also separated out the rooms likely to have sensor issues into their own spreadsheet based on certain conditions in the data. I am now making adjustments to the script to refine the visualizations a bit more. EDIT: I forgot to mention that I also started teaching a bit of matplotlib to the new recruits! I showed them my project and explained how it works. Also, here are some sample images of what my visualizations will look like: 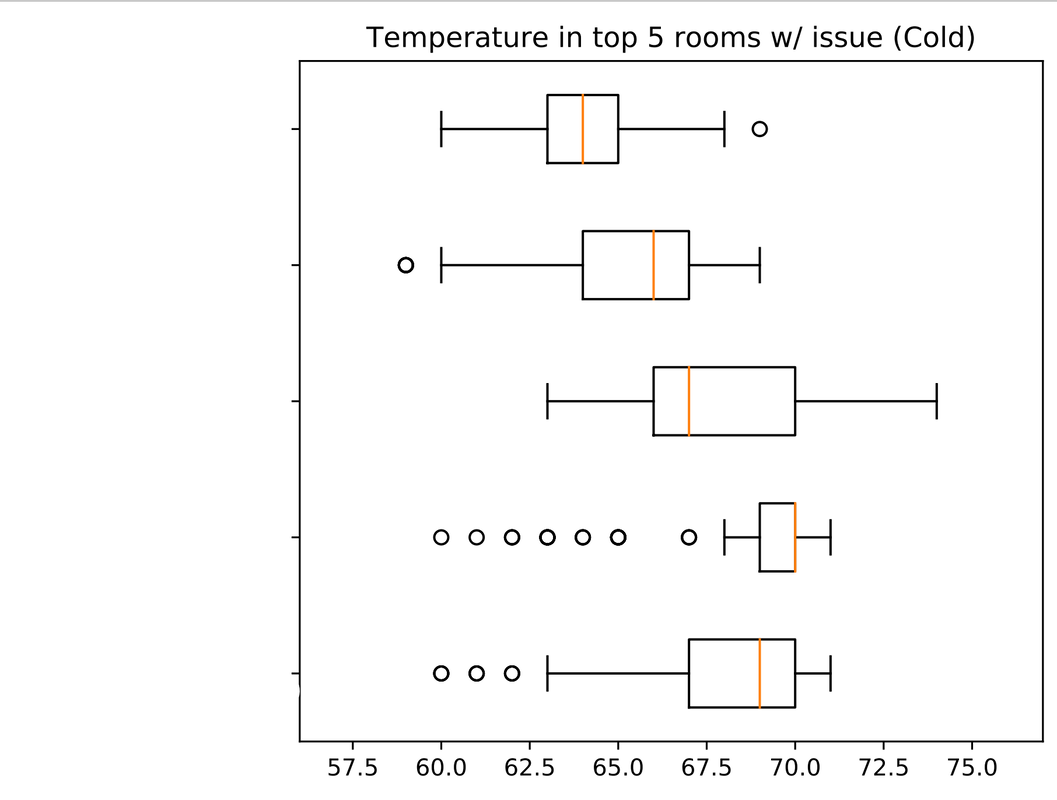 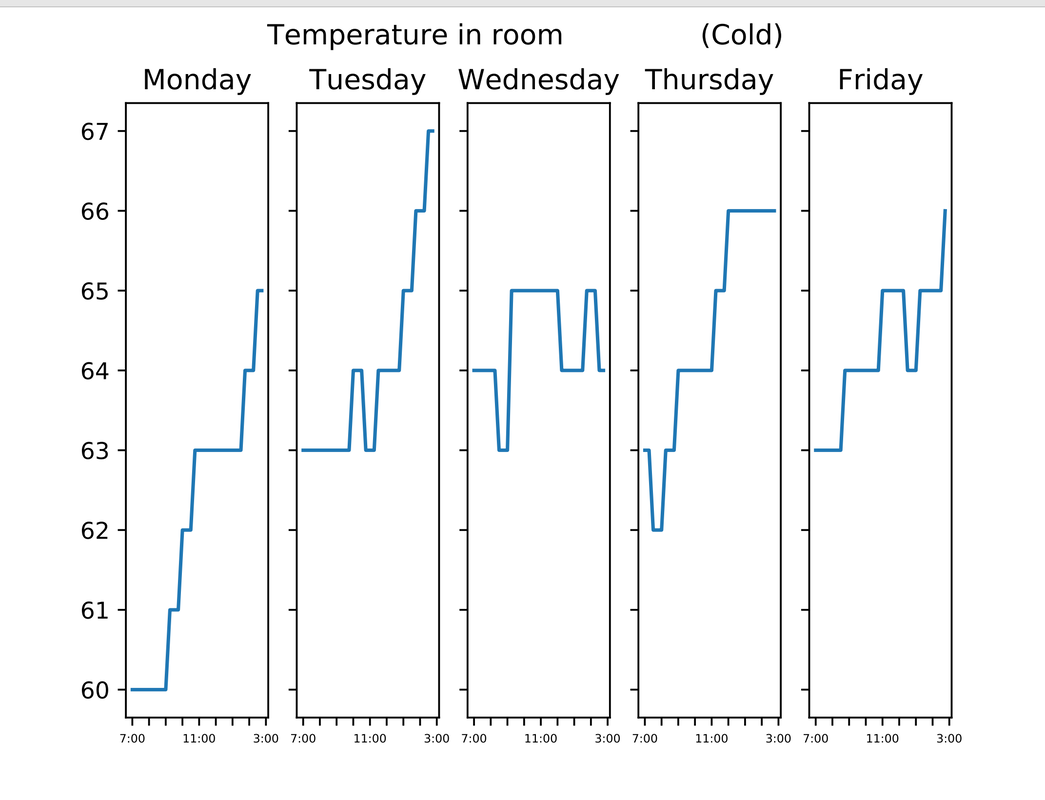 A few important things happened over the last couple of weeks, so I will update this blog on them here.
1. School is ending this week, so in order to give the new recruits a bit of a break, the Energize recruit class will meet only once every 3 weeks. However, the plan is for the students to work on their projects of interest in their small groups. 2. I finished testing the historical data version of the weekly report -- it is completely free of bugs and usable. 3. I will be working with a PhD student, Kate, through the BU URBAN program! We met yesterday to discuss how I can apply my project to a health context. Kate is currently studying the ways to use carbon dioxide as an indicator of ventilation quality, which is particularly relevant to places looking to safely reopen during the COVID-19 pandemic, as bad ventilation can increase the risk of disease spread. Therefore, we are currently looking into connecting that aspect of things to the reporting engine. On Monday, I continued training the new recruits. Before class, I spent about an hour developing challenges for them to take on (and corresponding solutions) using the student database. (You can see them at my GitHub repo here.)
When class started, they were divided into two groups (one for water consumption and one for political data). Each group worked on challenges that were tailored to the type of data they wanted to work with. As some students have Chromebooks and are using repl.it (an absolutely fantastic tool!), we tried to integrate the database into repl. When this did not work, I asked them to collaborate with their groups through repl, such that the person with the capacity to run code on the database would test each time they were ready. This worked much better, but figuring out the setup took a bit more time than expected. Back in September, I had figured out how to read from a sqlite file based on the example file in the database's Google Drive folder. In order to give the new recruits an exercise in "real-world" problem-solving (as opposed to a classroom-like environment), I gave them the same challenge to start, having them glean knowledge from the example rather than teaching it to them directly. Interestingly, both groups were getting errors when their code was perfect; we eventually realized that the databases had somehow become empty when they were copied into the repository. I am really proud of both groups for adapting really well to both the challenge and the technical issues that came up along the way. The rest of the challenges involve using the pandas library -- I can't wait to see where they go with them next Monday! (Also, keep on the lookout for blog links next week!) Today, I worked for about an hour on debugging the Weekly Report. My main objective was to fix the incorrect values in the Days with Problems column, and I'm happy to say that I succeeded in debugging this error!
Luckily, I realized that I still had the code for the all_data DataFrame (the one I had previously used to get the correct Days With Problems values), albeit commented out, so I first un-commented out that code. Once I had that set up, I had to figure out exactly what was being stored in all_data and how I was going to merge the all_data table with my new weekly_log table. Once I had made sense of the data, I cleaned up the merge from which the DataFrame originated, and finally, I had to use a series of groupby commands to isolate just the day for each problematic interval and find the number of unique days belonging to each room. This took a few tries to get right. Finally, I merged the new DataFrame into the weekly_log. After checking back against my manually calculated test data, I came to the conclusion that the error had been fixed. Today, I worked for about an hour on debugging the Weekly Report.
I discovered that the issues with timestamps were actually human errors, not programmatic errors. However, I looked deeper into the discrepancies in the number of days with problems. This number is too high in the program's results because it counts any day on which the room has data instead of filtering out which days have problems. This should not happen because Task II filters out any intervals that don't have problems. At first, I thought that perhaps when I reference the old database in Task IV, I unknowingly bring back the days without problems. I tested this suspicion out by using the debugger and some strategically plotted breakpoints. First, I tried breaking at the end of the "Task III" portion of the code, which led me to discover that the DataFrame at the end of Task III also contained the unproblematic intervals. This meant that the problem was not in Task IV at all -- it had to be earlier, since the data being aggregated in Task IV already had the unproblematic rooms. This couldn't be possible, because Task II should filter it out before it goes into the daily database in Task III... however, when I broke at Task II, I finally realized the issue. Sometime in January, I had changed the central DataFrame of Task III to include all intervals, not just problematic ones, so that I could find the true highest and lowest values. However, I had not realized that the "Days With Problems" column would be aggregated incorrectly. Now that I know the origin of the problem is not with the switch to the historical report, my task is to develop a solution that correctly counts the number of days with problems. |
AuthorI'm a high school senior and programming enthusiast. Archives
March 2022
Categories |
 RSS Feed
RSS Feed
